I Built a Search Agent. Then I Spent Months Teaching It When Not to Answer

The hardest feature in production RAG is not retrieval. It is judgment.
A funny thing happens when you build your first search agent.
At first, it feels magical.
You take a messy pile of knowledge: PDFs, internal templates, business rules, operational instructions, store information, support documents. You chunk everything. You embed it. You retrieve the closest passages. You send them to an LLM. The model writes an answer.
In a demo, everyone smiles.
Then real users arrive.
They ask half-questions. They use old names for new processes. They ask about rules that changed last week. They mix several requests in one sentence. They paste personal information. They ask things that look answerable, but are not actually supported by the documents.
And the system does exactly what you built it to do.
It answers.
That was the uncomfortable lesson behind my Paris Machine Learning Meetup talk:
A good search agent is not the one that always answers.
It is the one that knows when it has enough evidence, when it needs a tool, and when it should stay silent.
That sentence sounds obvious now. It did not feel obvious at the beginning.
At the beginning, I thought I was building a better search system.
I was actually building a decision system with a mouth at the end.
Version 1: Naive RAG, the beautiful liar
The first version was the classic RAG proof of concept.
Indexing. Retrieval. Generation.
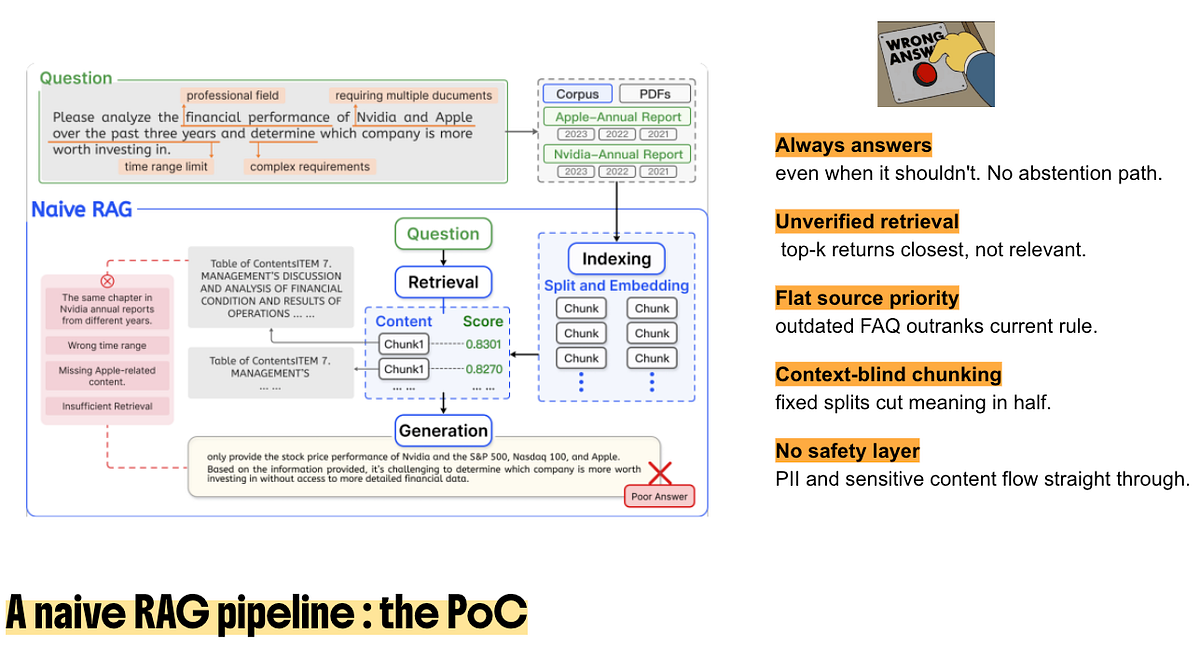
That is the basic recipe: split documents into chunks, compute embeddings, retrieve the top-k closest chunks, inject them into the prompt, generate an answer.
It is simple. It is fast to prototype. It gives impressive demos.
It also has a dangerous default behavior: it always tries to answer.
That is fine when the question is clean, the documents are fresh, and the right answer is sitting in one obvious paragraph.
Real customer-service knowledge is not like that.
In practice, the naive pipeline had five problems.
First, it had no abstention path. If retrieval returned something, the model had to say something.
Second, retrieval was unverified. Top-k returned the closest chunks, not necessarily the relevant ones. Similarity is not authority. A paragraph can be semantically close and still be the wrong source.
Third, source priority was flat. An outdated FAQ, a current operational rule, and a generic email template could all compete as if they had the same weight.
Fourth, chunking was context-blind. A fixed split can cut the meaning in half. The retriever sees a fragment. The generator pretends it saw the rule.
Fifth, there was no safety layer. Personal information, sensitive content, and risky requests could flow straight through the system.
The mistake was subtle but important:
I treated retrieval as evidence.
It is not.
Retrieval is only a candidate. Evidence starts when the system can explain why this source should be trusted for this question.
For a search agent, confidence without provenance is just charisma.
And charisma is not enough.
Version 2: Advanced RAG, or optimizing the wrong thing
The obvious reaction is to make retrieval smarter.
So you add query rewriting. You add reranking. You improve chunking. You build a hierarchical index. You try hybrid search. You tune the retriever. You make the pipeline look more serious.
And yes, it helps.
But it does not fix the core problem.

Advanced RAG improves the search process. It does not automatically improve the decision process.
A reranker can tell you which chunk looks more relevant. It cannot decide that a current policy should beat an old PDF unless you encode that rule somewhere.
A query rewrite can make the user’s question clearer. It cannot tell you whether the question is underspecified.
A hierarchical index can improve recall. It cannot decide whether the retrieved evidence is sufficient to answer.
This is where I started to feel the ceiling.
The system became better at finding plausible context, but it still had the same blind spot:
It was built as a line.
Question in. Retrieval. Generation. Answer out.
That linear design is comfortable. It is easy to draw. It is easy to demo. It is also too weak for many real situations.
Because real questions do not all need the same pipeline.
Some questions need document retrieval.
Some need structured SQL lookup.
Some need clarification.
Some need moderation.
Some need escalation.
Some should not be answered at all.
If every question goes through the same pipe, the system is not intelligent.
It is just consistent.
Consistently wrong is still wrong.
Version 3: Modular RAG, when the system gets a spine
The shift happened when I stopped thinking of the agent as a chatbot with search.
I started thinking of it as a control system.
That is why the modular RAG framing was useful to me. Instead of treating RAG as one “retrieve-then-generate” chain, modular RAG decomposes the system into modules, sub-modules, and operators. A system can route, branch, loop, verify, call tools, and choose different flows depending on the question.
In plain English:
Not every question deserves the same architecture.
That changed the design.
The modular version had five principles.

1. Route before you retrieve
Before searching, the system should ask: what kind of question is this?
Is it asking for a policy? A store detail? A product fact? A template? A procedure? A question involving personal data? A question that needs structured data?
Different questions need different paths.
A policy question should not be handled like a store-location question.
A structured availability question should not be answered from a random PDF.
A sensitive question should not be treated as normal text.
Routing is not a luxury feature. It is how you stop the system from using the wrong brain.
2. Trust sources, not just similarity
Vector similarity is useful, but it is not a source-of-truth strategy.
A current operational rule should beat an old FAQ.
A validated database should beat a marketing paragraph.
A dated template should not override a newer policy.
This means the retrieval layer needs metadata: source type, freshness, authority, document family, business owner, validity period.
The ranking function should not only ask:
“Which chunk is closest to the question?”
It should also ask:
“Which source is allowed to answer this question?”
That one change makes the system feel less like semantic search and more like knowledge governance.
3. Call tools when documents are the wrong interface
Some facts do not belong in prose.
Store hours, product availability, client order status, country-specific constraints, operational tables, internal taxonomies: these are structured facts.
For those, the answer should come from a tool, not from an LLM guessing through text.
In the modular system, retrieval is only one possible action.
Sometimes the right path is SQL.
Sometimes it is a keyword search.
Sometimes it is a rules engine.
Sometimes it is a human escalation.
The agent should not be proud. It should use the right instrument.
4. Filter both input and output
The system needs safety gates before and after generation.
Before retrieval, it should detect sensitive content, personal information, and requests that require special handling.
After generation, it should verify that the answer is grounded in the retrieved evidence.
This is not just about “AI safety” in the abstract. It is about operational reliability.
A support assistant should not leak personal information.
It should not invent rules.
It should not answer from weak evidence.
It should not sound certain when the underlying sources disagree.
In production, the answer is not the product.
The controlled answer is the product.
5. Make abstention explicit
The most important path in the system is the one people forget to draw:
No evidence, no answer.
Not every failure should become a confident paragraph.
Sometimes the right output is:
“I found information about online returns, but I did not find evidence for this specific in-store case.”
Or:
“The available documents disagree. I cannot answer reliably without checking the current policy.”
Or:
“This requires structured store data. I need to call the store database.”
Or simply:
“I do not have enough evidence to answer.”
That is not a failure of the system.
That is the system protecting the user from false confidence.

Abstention is not silence. It is a designed behavior.
There is a bad version of abstention.
The annoying version.
The version where the assistant refuses everything, hides behind generic safety language, and makes users feel like they are talking to a legal department wearing a chatbot costume.
That is not what I mean.
Good abstention is specific.
It explains what is missing.
It says what evidence was found.
It says what would be needed to answer.
It gives the next best action.
A good search agent should not just say “I don’t know.”
It should say:
“I don’t know because the retrieved sources do not contain X, and the closest available document only covers Y.”
That is a very different user experience.
One is a dead end.
The other is controlled uncertainty.
The part nobody wants to talk about: evaluation
Once you build a modular RAG system, evaluation gets harder.
With a naive pipeline, you can evaluate retrieval and generation separately. It is not perfect, but at least the shape is clear.
With modular RAG, you have more moving parts:
Routing. Retrieval. Source selection. Reranking. Tool calls. Moderation. Verification. Abstention.
There is no single metric that captures the whole thing.
You need a test set with different types of questions:
Answerable questions.
Unanswerable questions.
Underspecified questions.
Questions requiring tools.
Questions involving stale sources.
Questions where the top semantic match is not the authoritative source.
Questions where the safe behavior is to ask for clarification.
The system should not only be rewarded for correct answers.
It should also be rewarded for correct non-answers.
That is the part people underestimate.
A search agent that answers 95% of questions may look better than one that answers 80%.
Until you inspect the 15% it should have refused.
In real systems, the cost of a wrong answer is not symmetric with the cost of saying “I need more evidence.”
That trade-off is the product decision.

Modular RAG is not magic
I do not want to oversell it.
Modular RAG is not a free upgrade.
More components mean more things to monitor and debug.
Every router, reranker, verifier, and tool call adds latency.
Every abstention threshold creates a new tuning problem.
Over-refusal can frustrate users as much as wrong answers.
And the architecture only pays off if you build feedback loops around it.
You need logs.
You need user feedback.
You need failure analysis.
You need to know when the router picked the wrong path, when retrieval found the wrong source, when the verifier was too strict, when the assistant refused a question it could have answered.
The system does not become reliable because it has more boxes in the diagram.
It becomes reliable when each box has a job, a metric, and a reason to exist.

What I learned
The prototype is not the product.
Top-k is not truth.
Reranking is not understanding.
Similarity is not authority.
A bigger context window does not fix weak evidence.
“No answer” must be designed, not prompted as an afterthought.
And the hardest question in RAG is not:
“Can the model answer?”
It is:
“Does the system have enough evidence to deserve an answer?”
That is the line between a demo and a reliable assistant.
I started by building a search agent.
Then I spent months teaching it when not to answer.
And honestly, that was the real work.
Credit : For the architecture framing, I build on Gao et al.’s Modular RAG, which reframes RAG as a reconfigurable system of routing, retrieval, tools, verification, and control flows rather than a simple “retrieve then generate” pipeline.


