Why there are so many Imposters in Data Science?
Over the past few years, We have all witnessed an explosion in the number of articles, videos, online courses and job offers that are all talking about "Data Science" and Data scientists".
The trend above, shows how the world got interested in the term data science over time.
What we see here is a proof that around 2011-2012, the world became more and more interested in searching about data science.
I have written previously about this, you can read the whole article here.
It is a bit difficult to put a general definition to the Data Science field as many companies and data scientists prefer to generalize and to include various activities and tasks to suit the reality, the needs and the structure of their companies.
Data Science isn't a nice thing. Most of the tasks and objectives and scope of data science has been covered by many other people under different names.
You can have a BI engineer, data warehouse specialist, statistician, data analyst, data base manager, reporting and dashboard specialist, business analyst..etc
The thing is, the situation is still the same in some companies, as these firms have worked very well with their existing teams, they did not change the company's structure to include job titles that already exist under other names.
What changed maybe is the ways that companies are looking at data.
It was always an objective to a company to make smart decisions. usually these decisions are motivated by a market reality, management expertise and intuition, and by some data extrapolations and forecasts.
Data was a tool, numbers were used as an additional argument to support decisions, but when the numbers were not matching with that the feeling of the market is going, most companies ignore them ( they still do that until now by the way!)
It took a while and I am not sure exactly when it started, but companies began to consider "Data Driven Decisions", and they started trusting the numbers and started making more and more decisions based on the numbers rather than on pure intuition or personal opinions.
Data Driven companies became the new thing and all CEOs and high management staff started pushing thier teams to focus more on providing insights and conclusions based on deep analysis and scientific approaches. And this is how it was possible for "Data" to become a "Science".
But what are the required or desired skills to do science with data?
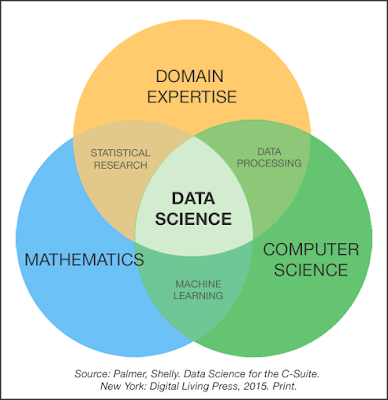
There is an easy way to explain data science (I admit, it is easy but very confusing to non-technical people). If I can explain it in simple words, i would say that it is very important to have Math/Statistics background, I say this knowing that some people may disagree with me on the basis that there are many DS that made it with physics, computer science or biology backgrounds.
Computer Science skills are also important, having the adequate programming skills and the knowledge of basic and advanced concepts are something crucial for a successful data scientist.
Now, the final part is not mandatory for beginners, but it is very useful to have extensive and in-depth domain expertise. As the Data and numbers "Reference" in the company, you have to be able to tell in there are anomalies or irregularities in the KPI's and in the data results.
Understanding the major KPI's for any domain (like churn for telecom, CLV for e-commerce.. etc) is important if you will be making reports and conclusions that will provide valuable insights to decisions makers.
I cannot say that there isn't any confusion. It exists and it's the main factor that contributed to all this hype.
People still up to this moment do not know what exactly is data science, and what is the best way to understand and approach this subject.
The same thing that happened with big data ( see my previous thoughts on this subject here )
I also believe that the same hype is now surrounding the "Crypto Currency" world and making it more and more confusing to regular people to understand (thanks to all "Bubble or no Bubble" buzz articles)
We all want to be relevant and by nature we all want to be appreciated for what we are and/or what we do. We also want to be associated with success and fortune. And this is no exception to highly educated and smart people.
The main reason to having many imposters in this field is the very famous saying "Fake it until you make it". Most ambitious people will believe in this approach because it is very motivating to people that lack the skills to become a data scientist.
Yes you can fake it.. but down the road, you are putting so much at risk. Your reputation, your career and all your ambition is in danger of you taking a job or a project where you still have no clue what to do and how to do it, and rely on MOOCs and tutorial videos to lean very hard and complex notions.
https://caitlinhudon.com/2018/01/19/imposter-syndrome-in-data-science/
 |
| “Portrait of an Impasto Imposter” by Eric Wayne |
This explosion has attracted people curiosity, and resulted in more and more "hype" around this "new" Science ( I will explain later why I put "new" between " " )
The trend above, shows how the world got interested in the term data science over time.
What we see here is a proof that around 2011-2012, the world became more and more interested in searching about data science.
What is Data science after all?
I have written previously about this, you can read the whole article here.
It is a bit difficult to put a general definition to the Data Science field as many companies and data scientists prefer to generalize and to include various activities and tasks to suit the reality, the needs and the structure of their companies.
Data Science isn't a nice thing. Most of the tasks and objectives and scope of data science has been covered by many other people under different names.
You can have a BI engineer, data warehouse specialist, statistician, data analyst, data base manager, reporting and dashboard specialist, business analyst..etc
The thing is, the situation is still the same in some companies, as these firms have worked very well with their existing teams, they did not change the company's structure to include job titles that already exist under other names.
What changed maybe is the ways that companies are looking at data.
It was always an objective to a company to make smart decisions. usually these decisions are motivated by a market reality, management expertise and intuition, and by some data extrapolations and forecasts.
Data was a tool, numbers were used as an additional argument to support decisions, but when the numbers were not matching with that the feeling of the market is going, most companies ignore them ( they still do that until now by the way!)
It took a while and I am not sure exactly when it started, but companies began to consider "Data Driven Decisions", and they started trusting the numbers and started making more and more decisions based on the numbers rather than on pure intuition or personal opinions.
Data Driven companies became the new thing and all CEOs and high management staff started pushing thier teams to focus more on providing insights and conclusions based on deep analysis and scientific approaches. And this is how it was possible for "Data" to become a "Science".
But what are the required or desired skills to do science with data?
There is an easy way to explain data science (I admit, it is easy but very confusing to non-technical people). If I can explain it in simple words, i would say that it is very important to have Math/Statistics background, I say this knowing that some people may disagree with me on the basis that there are many DS that made it with physics, computer science or biology backgrounds.
Computer Science skills are also important, having the adequate programming skills and the knowledge of basic and advanced concepts are something crucial for a successful data scientist.
Now, the final part is not mandatory for beginners, but it is very useful to have extensive and in-depth domain expertise. As the Data and numbers "Reference" in the company, you have to be able to tell in there are anomalies or irregularities in the KPI's and in the data results.
Understanding the major KPI's for any domain (like churn for telecom, CLV for e-commerce.. etc) is important if you will be making reports and conclusions that will provide valuable insights to decisions makers.

How confusion made it all possible?
I cannot say that there isn't any confusion. It exists and it's the main factor that contributed to all this hype.
People still up to this moment do not know what exactly is data science, and what is the best way to understand and approach this subject.
The same thing that happened with big data ( see my previous thoughts on this subject here )
I also believe that the same hype is now surrounding the "Crypto Currency" world and making it more and more confusing to regular people to understand (thanks to all "Bubble or no Bubble" buzz articles)
Why so many imposters?
The main reason to having many imposters in this field is the very famous saying "Fake it until you make it". Most ambitious people will believe in this approach because it is very motivating to people that lack the skills to become a data scientist.
Yes you can fake it.. but down the road, you are putting so much at risk. Your reputation, your career and all your ambition is in danger of you taking a job or a project where you still have no clue what to do and how to do it, and rely on MOOCs and tutorial videos to lean very hard and complex notions.
How to tell if someone is a DS imposter?
Well, this is not an easy task, and I don't believe that you should be out hunting fake data scientists.
It always depend on where you are standing.
If you are a manager, trying to hire a data scientist, the best approach for detecting good/not so good data scientist, is to make sure that your hiring process takes into consideration the technical aspects of the job.
Doing HR interviews and asking brain-teasers is fun, but it will be a waste of your time if you only base your decision on first impressions.
I personally do the following steps to determine if a person is a good fit for my team:
It always depend on where you are standing.
If you are a manager, trying to hire a data scientist, the best approach for detecting good/not so good data scientist, is to make sure that your hiring process takes into consideration the technical aspects of the job.
Doing HR interviews and asking brain-teasers is fun, but it will be a waste of your time if you only base your decision on first impressions.
I personally do the following steps to determine if a person is a good fit for my team:
- general interview, to asses motivation, attitude, energy level and overall knowledge of the domain.
- technical interview: Stats and math: depending on the position, a basic/ advanced background of statistics and math is mandatory if the person you are hiring is going to work with models, descriptive stats and is going to work on reports , visualizations and summaries.if the job is intended to hire someone that will work on data engineering, cleansing and integration, the technical interview should be more focused on this area, but it does not hurt to know that the person can make the difference between mean and median, and can also do quick and dirty reports (SQL is the key here).
- third interview is a final step, and it should be about business knowledge and understanding. This is not a deal breaker when hiring juniors, or hiring people from other industries.The most important this is that you take into account in the on-boarding process that this person will require a transition period, to understand key business concepts, numbers and focus areas.
How to avoid being an "Imposter"
There are known things that any person can make sure they don't happen, to ensure that no one will consider you as an imposter (in Data Science or in any other field):
I don't know about you, but I have a constant habit of never pretending that i know more than I really know.
It is very recurrent when meeting with people in conferences or events, that someone will come up and start talking about things that sound very interesting, just so you find out after about 2 minutes that all of what this person is saying.. is similar to what would my rabbit say about relational data bases...
It will ruin your reputation in the long term if you say that you did or you can do things, and then when you enter into deep details, the only info you know are what you read in a TechCrunch article.
1- Don't be a Know-it-all:
I don't know about you, but I have a constant habit of never pretending that i know more than I really know.
It is very recurrent when meeting with people in conferences or events, that someone will come up and start talking about things that sound very interesting, just so you find out after about 2 minutes that all of what this person is saying.. is similar to what would my rabbit say about relational data bases...
It will ruin your reputation in the long term if you say that you did or you can do things, and then when you enter into deep details, the only info you know are what you read in a TechCrunch article.
2- Learn what you don't know and ask questions:
Yes! You have to be highly motivated, not afraid to ask questions and to seek information from every source.
This field is very large and immense and it takes months and years of practice to be good at what you are doing. So never stop learning and never stop asking questions.
Woking on side projects and online challenges like Kaggle are a good thing too.
This field is very large and immense and it takes months and years of practice to be good at what you are doing. So never stop learning and never stop asking questions.
Woking on side projects and online challenges like Kaggle are a good thing too.
3- Teach / share and spread your skills in the community:
This is the final point, i think that the best way to learn is to teach. This does not mean that you will be a master of something while knowing nothing about it. But the best way to really know that you understand something is when you are able to explain it to others in simple terms and will a full detailed summary.
Doing blog posts, writing code, sharing and answering questions in online forums like Stackoverflow is a great way to learn about data science.
Finally, i really wish that more people get into this field with more desire to learn and to advance the technologies and the tools used.
I am willing to share/ help anyone that has a true desire to make a progress!
-- Acknowledgment note:
This article was inspired by the below post by @Caitlin Hudon, and i felt that I can add more to it! so thanks Caitlin for sharing this to the world !


